Platform
Resources


Just try two things, and see which one is better…well, mostly.
I first learned about the concept of A/B testing in college, when I was working for an eCommerce agency. I was a part-time intern at the ~10-person company, and one of my jobs was updating the detail pages for items sold on Amazon.
I didn’t get a ton of guidance on how to optimize the components of our listings. We were basically told to “make it look good,” given some examples, and encouraged to get as many listings done as possible.
One of my managers suggested that we A/B test some variables, things like pricing, item names, and more. When I asked them what A/B testing was, they said: “Well, you just try two things, and you see which one has a higher purchase rate.”
It felt revolutionary at the time. Unfortunately, that description left a lot of important information out—information that I would have to discover for myself someday, including statistics.
At the time, I would’ve benefitted from a course in A/B Testing 101.
What is A/B testing?
A/B testing, also known as split testing, is a method of comparing two versions of something and seeing which one drives more effective results.
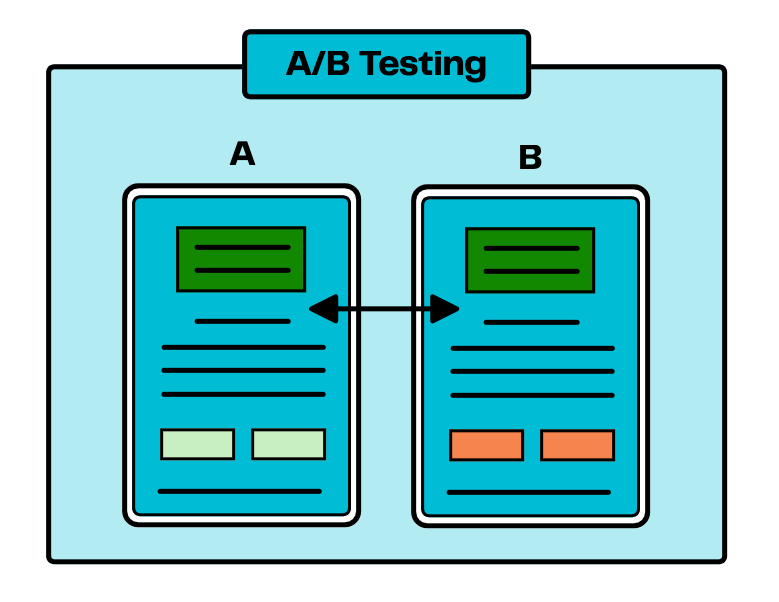
In this example, the designer of the webpage is trying to see which button is more effective in driving clicks: the blue button, or the green button. This is the simplest version of an A/B test and possibly the most frequently used example of all time.
The technique of providing two variants and selecting a winner has been widely adopted by software engineers, product managers, digital marketers, UX/UI designers, and even political candidates to refine user experiences and improve core metrics (such as engagement or conversion rate).
It’s a very helpful tool because it takes the guesswork out of product building: instead of relying on your intuition to pick a better treatment, you can just run a test and see which treatment works best.
🤖👉 Try now: Create your first A/B/n test with Statsig.
How A/B testing works in 5 steps
Most people’s understanding of A/B testing stops there. In reality, if you’re doing A/B tests correctly, there’s a lot going on under the hood.
In the rest of the article, I’ll outline how A/B testing actually works, introduce some common terms, and discuss some best practices. I’ll also be referring to A/B testing primarily in the context of developing a software application or website.
Step 1: Designing your A/B test
The design phase is where you lay the groundwork.
Begin by defining a clear, measurable goal. This could be reducing bounce rates, increasing the number of sign-ups, or improving the click-through rate on a call-to-action button.
Once the goal is set, identify which element(s) you think might affect this goal. For instance, if the goal is to increase newsletter sign-ups, you might test different placements of the sign-up form on your webpage.
Next, set a hypothesis. An example hypothesis could be “moving the sign-up form to the center of my page will increase sign-ups.” Having a clear, measurable hypothesis helps you communicate the value of the test you’re running to others and makes it explicit what you think will happen.
As a part of your hypothesis, you should also define success metrics. In this case, the success metric would be the sign-up rate.
Step 2: Building your test treatment
Typically, if you’re running an A/B test on your website or product, you already have a baseline: your current product. In A/B testing, this is called your “control.”
Next, you need to create a “test treatment.” This is the new treatment that you’ll show to users. By comparing the impact of the two treatments on your core success metrics, you’ll validate or invalidate the result of your test.
Once your two versions are ready, you’re good to start your test.
Step 3: Randomization and assignment
To run an A/B test properly, you need to randomly assign subjects into the two treatment groups.
Randomization is important because it helps mitigate any bias between the two groups. “Bias” refers to any characteristics of a group that could skew the result of the test you are running, that are unrelated to the experiment you’re running.
For example, let’s say you decide to keep your “power users” (users who log in every day) in your “control” group because you don’t want to bother them with new changes. You only assign new users to the “test” group. This would skew the results of your A/B test. A lot.
In software A/B testing, randomization can get complicated. For instance, you can use many different characteristics as units of randomization for A/B tests, like randomly assigning different organizations on your platform into treatment groups.
Note, though, that if there are any fundamental differences in the way these organizations interact with your product or software, your results will be skewed.
After your users have been randomized accordingly, they will be assigned to a treatment, meaning they are shown a specific version of an application or website.
Once a user is assigned to a treatment, they are typically kept in that treatment group for the duration of the test, so that the tester is able to see the impact of that treatment over an extended period of time.
Step 4: Tracking metrics for each group
The impact of the two treatments is measured using metrics.
Metrics are quantitative measures used to track and assess the status of a specific business process. In A/B testing, common metrics include conversion rates, click-through rates, bounce rates, and average time on page. These metrics help determine the effectiveness of the test variations compared to the control.
As an A/B test is run, the tester will “log” events for each user, and aggregate the metrics for each group. Over time, differences may emerge; these differences are referred to as the “lift” or “effect” of the various treatments.
However, it’s not enough to look at the averages in each group. There is natural variance in every A/B test you run; users will often behave in “random” or unexpected ways.
This is where statistics come in.
Read our customer stories
Step 5: Using statistics to measure impact
You can use statistics to estimate the effect of random chance in the aggregated results that you’re seeing.
Here’s how statistics are used to attempt to measure the actual impact of a test based on aggregated results.
Calculating results: The primary metrics of interest (like conversion rates) are calculated for both groups. For instance, if 5% of visitors in Group A and 7% in Group B complete a purchase, the conversion rates are 5% and 7%, respectively.
Statistical significance testing: Statistical tests, such as the t-test or chi-square test, are used to determine whether the differences in metrics between the two groups are statistically significant. This means determining whether the observed differences could have occurred by chance.
P-value: The p-value is calculated, which represents the probability that the observed results could have occurred under the null hypothesis (i.e., no real difference between groups). A commonly used threshold for significance is a p-value of less than 0.05.
Confidence interval: Confidence intervals are often calculated to provide a range within which the true difference between groups lies, with a certain level of confidence (commonly 95%).
Interpreting the results: If the results are statistically significant (p-value < 0.05), it can be concluded that the changes in the treatment group (B) had a significant effect compared to the control group (A). If not, it's concluded that there's no statistically significant difference.
Making decisions: Based on these results, decisions are made on whether to implement the changes tested in the treatment group across the board.
Statistics in A/B testing help teams make data-driven decisions by providing a systematic method for comparing two variations and determining if differences in performance metrics are due to the changes made or just random variations.
Why A/B testing matters
A/B testing can be transformative for people building software products.
For one, it unlocks a new level of data-driven decision-making for product teams: When teams are used to testing new ideas, they gain the ability to make decisions using the actual data on the feature they shipped, rather than debating the merits of shipping the feature at all. It also helps teams understand which features work and which don’t.
Further, A/B testing reduces the risks associated with making changes to your product or website, because you’re tracking the metrics associated with each release. If you accidentally roll something out that decreases a core metric, you can just roll it back! 🪄
Over time, this sort of speed and precision can lead to huge improvements in your team’s performance. It also makes life a lot more fun for engineers and PMs: Fewer meetings, more building things!
🗣️ Don’t take our word for it! Read our customer stories.
How to make A/B testing easy
If all of this sounds hard and complex, that’s because it can be! Building a full A/B testing toolkit for your team can take a ton of time and effort.
Fortunately, there are some great companies that have built A/B testing platforms (😏), so you don’t have to worry about randomization, maintaining a metrics catalog, or running stats tests.
At Statsig, our mission is to make data-driven decision-making available to anyone, which is why we’ve invested so deeply in building an easy-to-use platform that’s accessible to any team.
Get started now!
