Platform
Resources
Optimize AI products
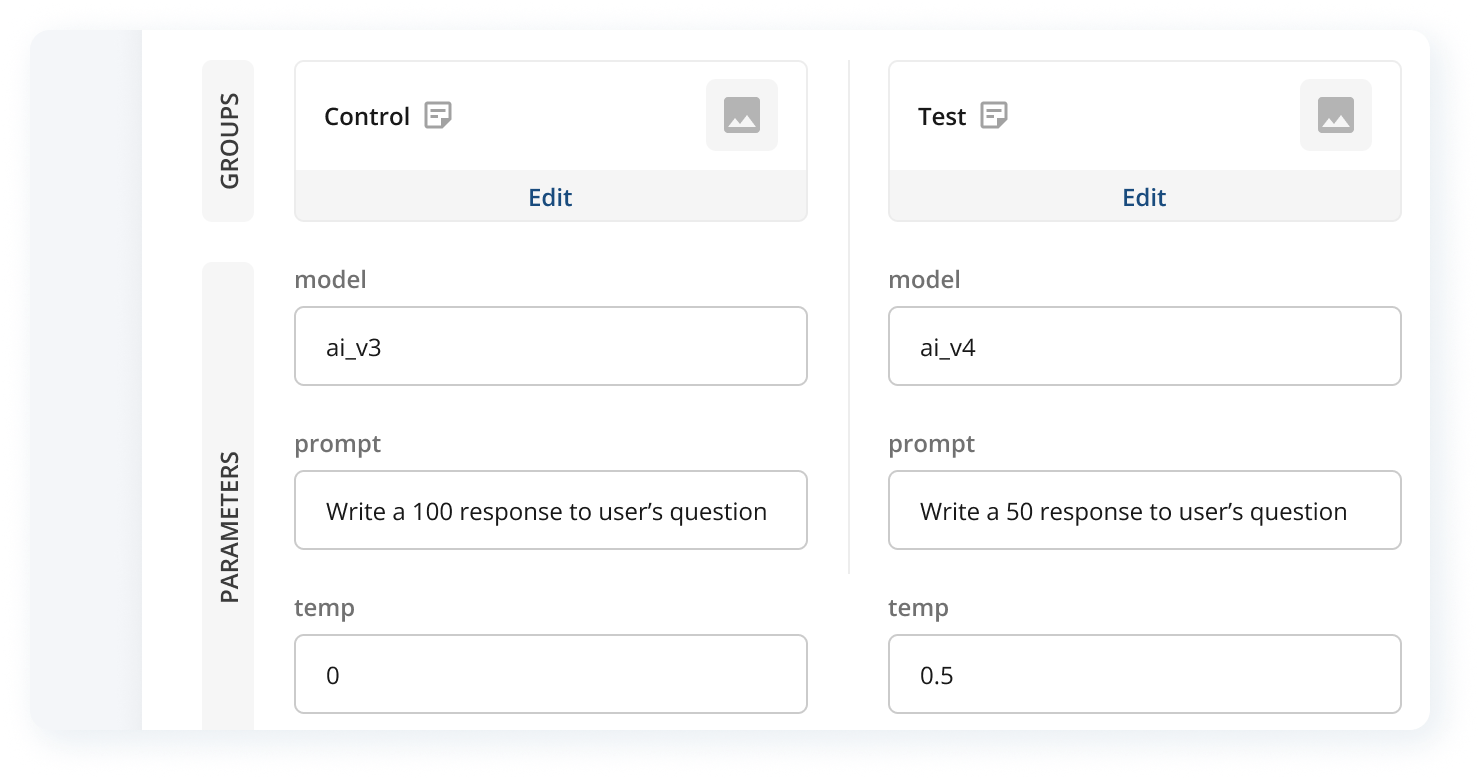
Experiment with different models & parameters
The difference between good vs bad is in finding the right combination of parameters. Conduct head-to-head comparisons of any model or model input to improve the usefulness of your AI application. Run concurrent tests in production.
Cost. Latency. Perf. Optimized.
Track model inputs, outputs, user, performance, and business metrics all in one place. Test different LLMs and parameters to optimize latency and cost. Balance quality and compute savings–does a cheaper model provide satisfactory performance in specific scenarios?

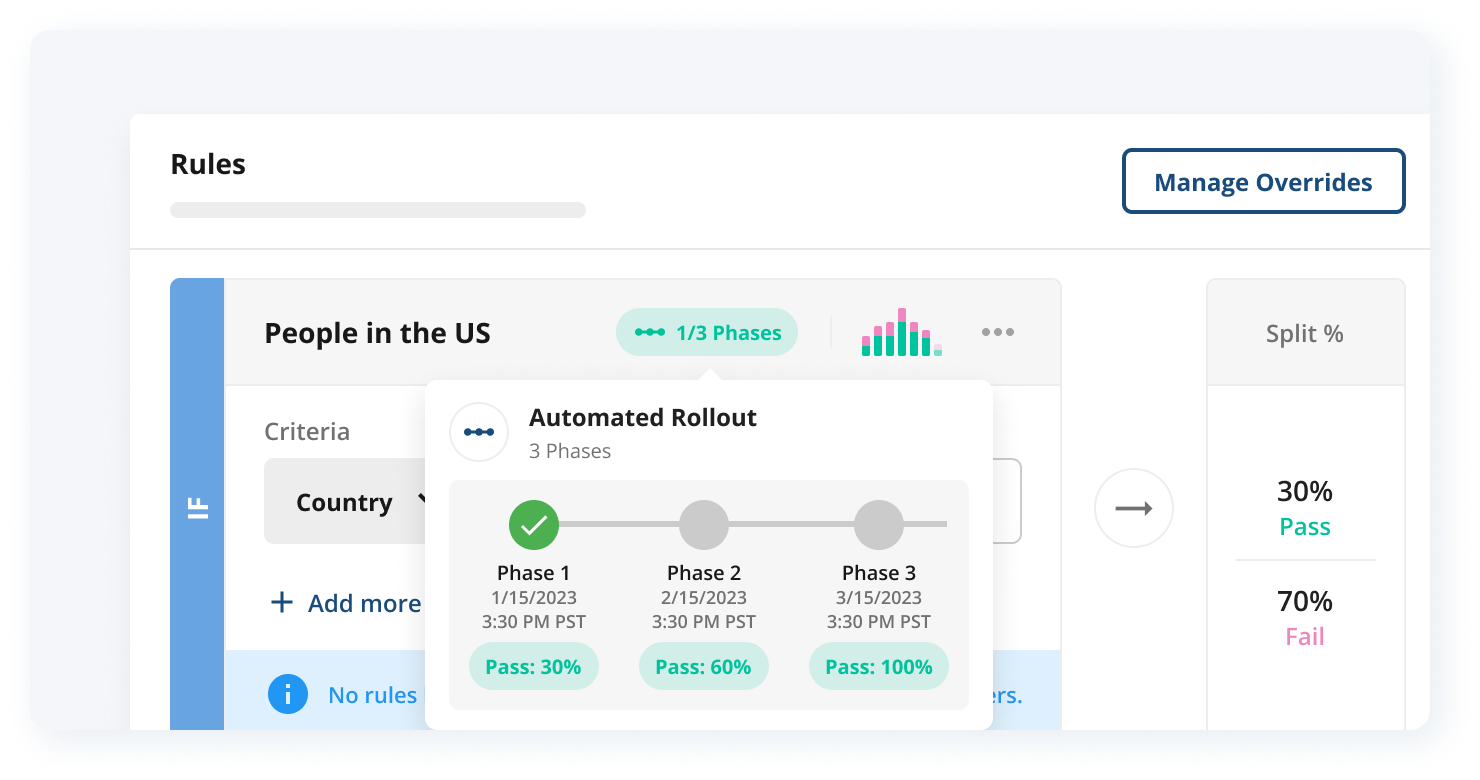
Instantly rollout new models as soon as they launch
Continuously release and iterate on AI features. Progressively rollout features, adjust app properties, measure the impact of their change, and rollback features without changing code.
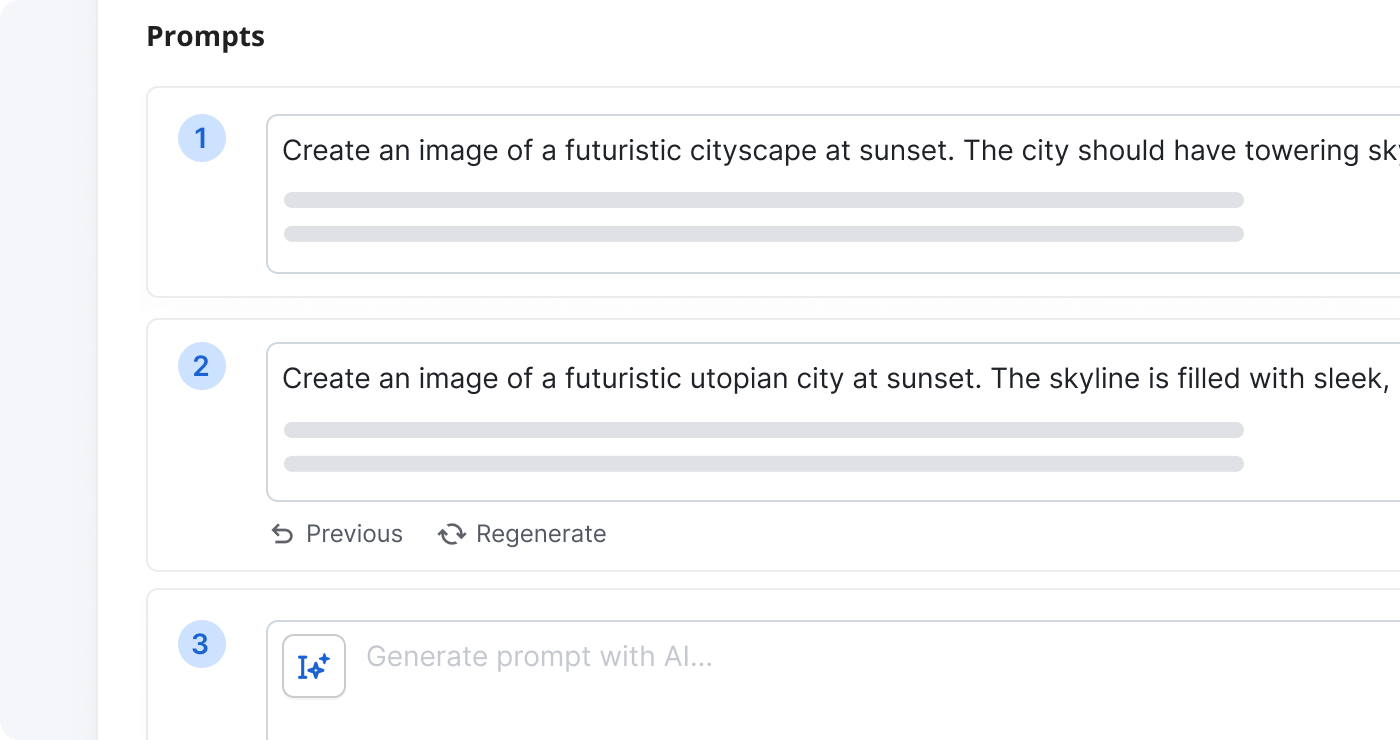
Improve the UX with prompt experiments
Prompts have an outsized impact on a model’s output. A/B test different phrasings and contexts for prompts—should you provide a starter prompt to the user and if so what should it be?
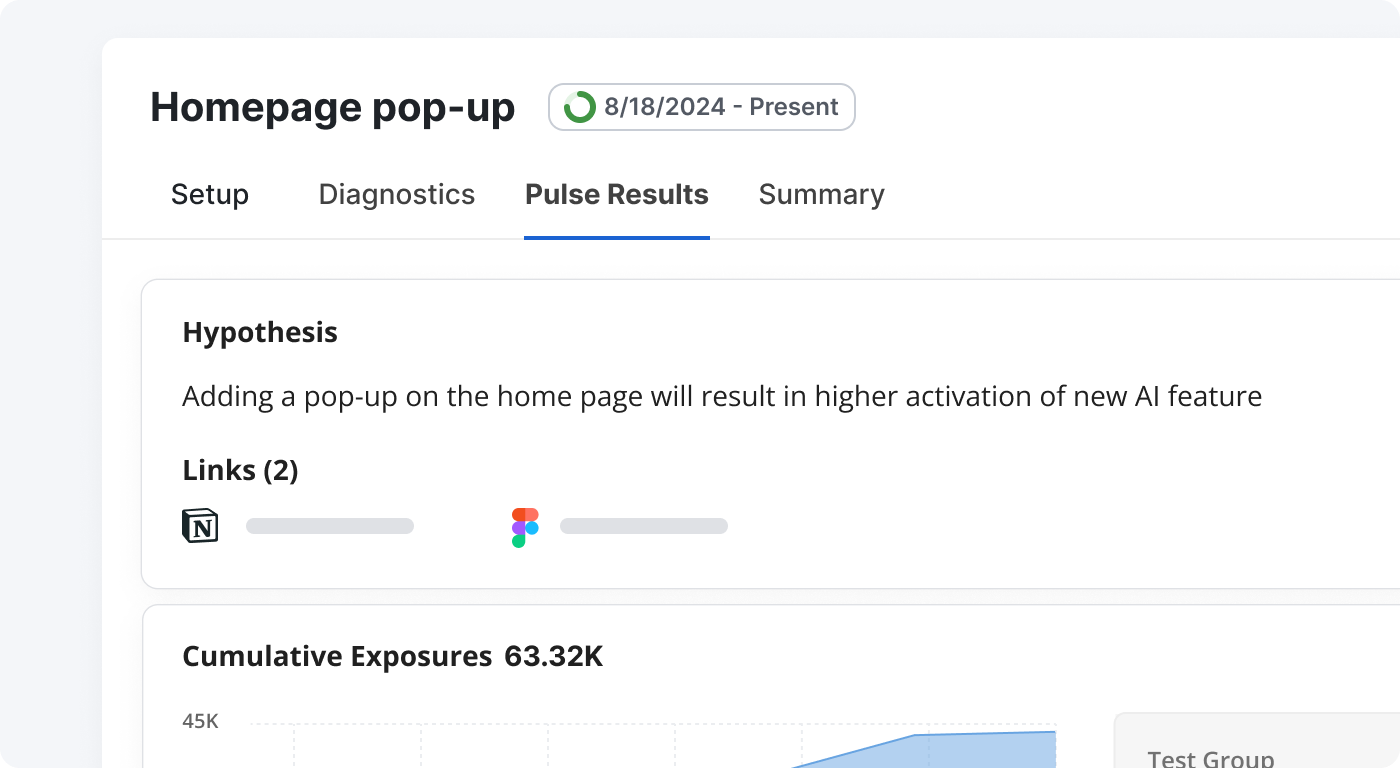
Drive usage of your AI features
Run growth experiments to reduce time to value, drive activations, boost stickiness and long-term retention. Test various pricing & packaging strategies—like setting limits for free users—to optimize ROI, and experiment on every stage of the customer journey.