Platform
Resources



The customer experience often spans across identity boundaries, devices, sessions, and the digital and physical worlds.
The notion of “identity resolution” in the SaaS world continues to be an elusive gold standard that businesses want to solve in order to understand the full scope of customer behaviors across all touch-points.
To that end, I promise not to use the term “omnichannel” in this blog. 🙂
This practice sounds somewhat simple at a high level, but there is a ton of variability regarding business use cases, user experience flows to solve for, and technological limitations.
A few disclaimers, debunkings, and considerations as we dive in:
No technology providers will solve every use-case and scenario perfectly, though many will make bold claims. There is a ton of nuance here and no one-size-fits-all solution.
The only true way to ensure a human is identified 1:1 consistently, is to only handle known identities (ie; all of your apps are behind auth, this way you have some sort of stored userID).
There is no magic wand available (although there are some sketchy fuzzy-matching CDP tools that are more marketing fodder than silver-bullet solutions, but we won’t discuss mirages here).
It is strictly impossible to reliably identify a single human interacting anonymously on two different devices that never identify themselves.
Identity boundary basics
Identity resolution generally pertains to how a platform will handle users crossing different technical boundaries.
There are many types of identities used to identify users, and this will vary across business models, verticals, and technology stacks. In the simplest, most common scenario, identity boundaries are defined by unknown and known users: Users begin their experience “unknown” to the business/application but later become known users by identifying themselves via logging in to create an account.
Unknown user: A user identified by a device-scoped identifier. This identifier is (temporarily) associated with the device the user is operating and doesn’t stick with the user permanently. (Examples: Statsig
stableIDor some first-party-managed cookie identifier.)Known user: A user that the application has seen before and can be identified by a single, immutable identifier that is permanently associated with the individual (Examples: An email address, customer_id, user_id that is stored somewhere in a database and becomes available to the application when the user logs in or identifies themselves).
What does this have to do with experimentation?
In experimentation, there are typically two core use cases where “identity resolution” is desired.
At the Point of assignment
TLDR: During application runtime, determining a user’s test group to decide which experience to show.
This use case describes the desire to ensure that a user is consistently assigned to the same test group and user experience, even when crossing identity boundaries, switching devices, or engaging disparate browsing sessions.
This use case is the more difficult to solve for because it requires a just-in-time lookup to determine the test group to assign the user (who may have previously been assigned to a given test group, and who may have crossed-identity boundaries since then).
This can require storing identity mappings and user assignments and referencing them at the point of assignment.
Key fundamentals
Understanding “deterministic assignment” is important to understanding the role that identity plays in test group assignment. TLDR; with any modern experimentation tool, test group assignment is determined based on a user’s identity. If that identity changes, test group assignment is subject to change.
Known users will always have an immutable ID associated with them, and experimentation tools will always deterministically bucket the user to the same test group given a fixed userID/email.
Unknown user identity becomes the crux of the challenge. When switching devices, browsers, environments (server vs. client), or clearing device storage, this ID will not persist.
At the point of analysis
TLDR: During stats engine computations, determining how to attribute events & metrics to a given individual.
If the user crosses identity boundaries, any subsequent events and metrics should be attributed to the same user and count toward the user’s originally assigned test group results.
Business metrics that are desired to measure experiments (e.g., subscription rate or estimated lifetime value) are typically calculated at the known user level. However, it’s common to run an experiment in a pre-authenticated state where the user is not yet known to the application.
Example ID resolution scenarios
Scenario 1: An unknown user visits the website and gets assigned to the “Test” group for nav_v2 experiment using via a deviceID. Shortly thereafter, the user logs in and continues to browse (All client-side, same device):
Point of assignment: They will continue seeing the “Test” experience because their original deviceID continues to persist in localStorage and will deterministically assign them to the test group each time the website is loaded. ✅
Point of analysis: The user’s ensuing activities will resolve to the same user and attribute to the proper “Test” group for results purposes because the events all contain the same deviceID identifier. ✅
Scenario 2: A user authenticates into a web app and is assigned to the “Test” group using a known customerID identifier.
Later, the user opens the mobile app, which is only accessible to known users. The user logs into the mobile app using the same login credentials, and the customerID becomes known to the mobile app.
Point of assignment: The user will continue seeing the same test experience because we have access to the same known identifier on both devices. They will deterministically be assigned to the “Test” group in both disparate sessions. ✅
Point of analysis: The user’s activities will resolve to the same user and attribute to the proper “Test” group for results purposes because the events all contain the same known identifier. ✅
Scenario 3: An unknown user visits the website on their desktop computer, and gets assigned to the “Test” group for nav_v2 experiment via cookieID identifier. Shortly thereafter, the user opens their mobile browser and visits the same website as an unknown user.
Point of assignment: The user may **be assigned to different experiences on the two separate devices. There is no possible way for a tool to identify this as the same user. The user was assigned two different values for
cookieIDin each session, and therefore may be subject to a different variation. 🚫Point of analysis: The two sessions are entirely separate and any events tracked will be attributed to each user session separately. There is no possibility of attributing all behavior towards the same individual. 🚫
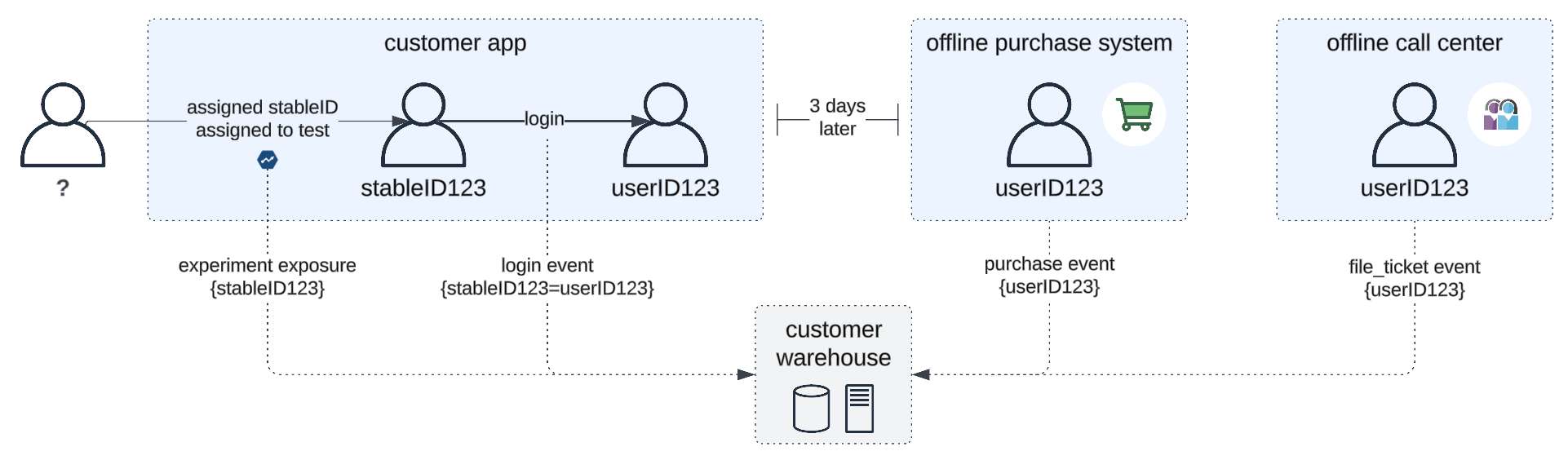
Scenario 4: An unknown user visits website on desktop, is assigned a random stableID in localStorage and gets assigned to the “Test” group for Discounted Shipping experiment.
The user subsequently logs in as cooper123 and continues to browse. Sometime after, the user opens their mobile app, logs in as user cooper123, and continues to interact.
Point of assignment: The user may be assigned to different experiences, given that the first experience was assigned using an anonymous identifier, and this identifier is not available on the user’s mobile device. We do, however, know that this person is
cooper123, and should continue receiving discounted shipping. ⚠️Today, experimentation platforms are not offering managed solutions to solve this. However, it is technically feasible via sophisticated engineering efforts and with some caveats. This would require an identity mapping store to perform a lookup prior to each test assignment to see if
cooper123was previously assigned (either via this known identifier or some other device-scoped identifier).
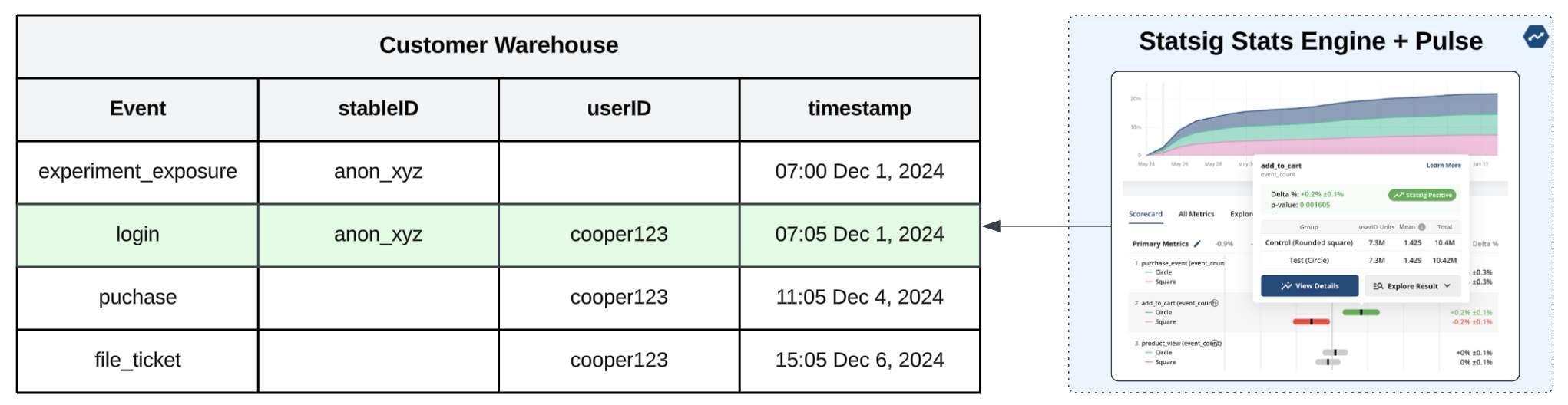
Point of analysis: Today, Statsig is one of the only platforms offering identity resolution for this use case with our data warehouse-native solution. If there is a record in your database that maps
stableID=anon_xyz→userID=cooper123, our stats engine can perform the necessary joins to properly calculate metrics containing either stableID or known ID in this case—meaning that in the example above, any subsequent interactions on mobile and any metrics created via offline systems (think purchase system data or call center data) with no knowledge of the originalstableIDcan be properly attributed to the individual represented bycooper123. Today, we support 1:1 mappings as detailed in our docs, but we plan on supporting more complex identity mappings in the future. ✅
In this final example, we can see the user was assigned using a device-level stableID, but there is a login event that allows us to map anon_xyz → cooper123. Statsig uses this to join on metrics that contain either ID type.
So much for magic, huh?
Statsig identity resolution diagrams
Questions?
If you’d like to learn more about how Statsig handles identity resolution—especially for your own use case—don’t hesitate to reach out.
Request a demo
