Platform
Resources

How Statsig uses query-level experiments to speed up Metrics Explorer
Historically, Statsig has focused its experiments on major changes.
Think fully redesigning the signup flow or completely changing the look and feel of the left nav bar. This is a super common challenge for B2B companies: a professional user base means that behaviors are pretty static and there isn’t the same scale of users that Google or Facebook have to detect small effects.
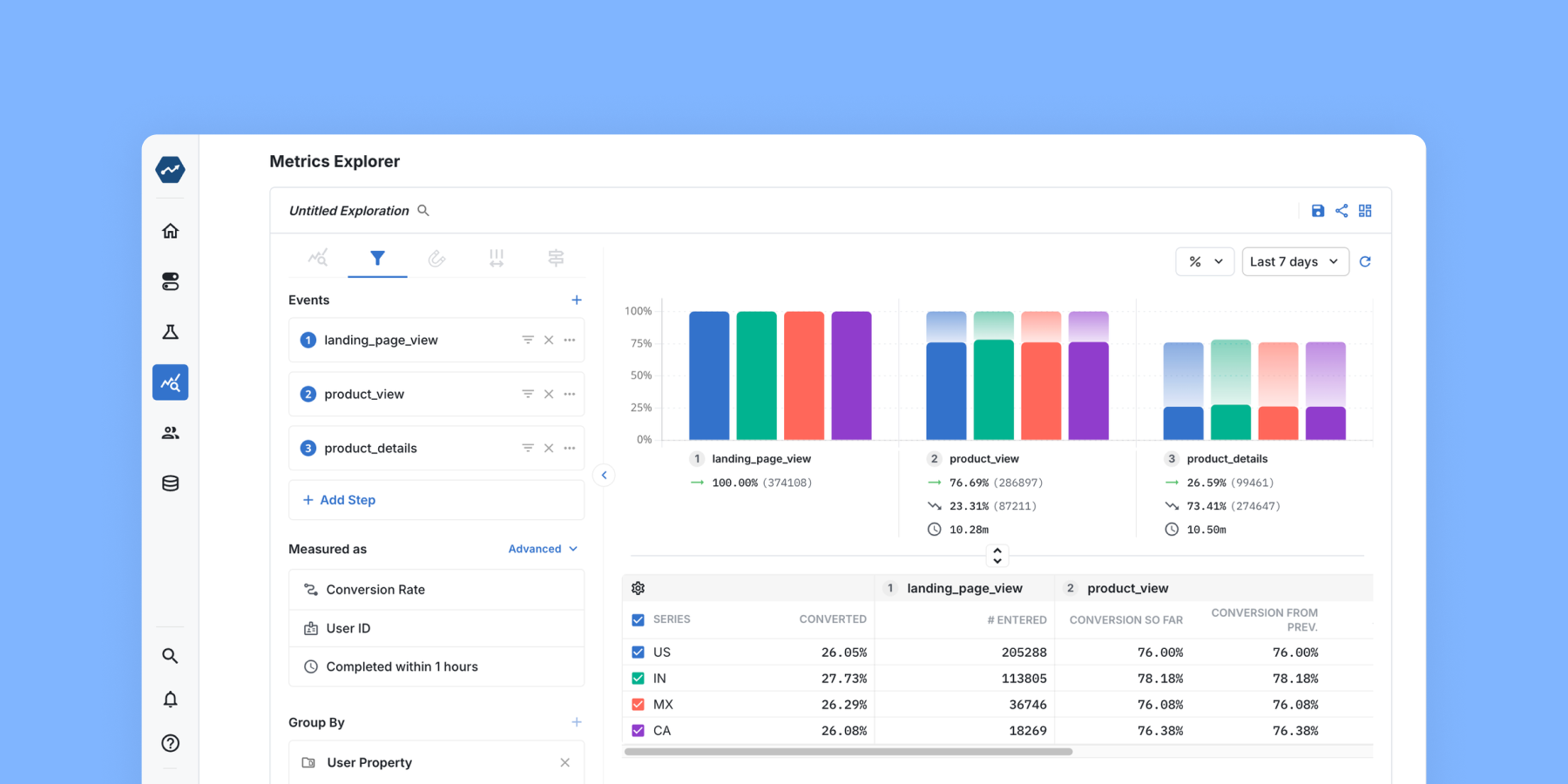
The typical unit of experimentation is the user—and for good reason! We want users to have a stable experience with the product and be able to measure long-term effects attributable to product changes. However, when we’re making performance improvements to Metrics Explorer queries, we’re less concerned with a stable user experience for experimentation purposes, and more concerned with making them faster in every scenario.
We’re forgoing the measurement of user-level outcomes to focus on making things faster at the query level. This unlocks experimentation where the unit of analysis is each query that is used to generate visualizations displayed in Metrics Explore. Now we can quickly get 10s of thousands of samples enabling us to quickly learn.
Have we tried being better at writing queries?
Intuitively, it feels like this kind of question should be knowable without A/B testing. Shouldn’t we just know through implementation best practices what factors and what cutoff points would make creating a temp table in Big Query worthwhile?
This ends up being a similar argument that folks make against product experimentation as a whole: “We don’t need to run experiments, I have good product sense.” This is despite evidence we have from industry that the success fate of experiments ranges from 8% - 33% depending on the product and context (see Kohavi, Deng, Vermeer paper).

There are a few reasons why running an experiment can be helpful here in particular:
Faster time to learning: Analytically determining all of the scenarios where one methodology works better than another is time-consuming to evaluate, experimentation allows you to empirically observe where one methodology is better than another.
Non-experts can test out potential performance improvements: This allows folks who may not be as familiar with performance optimizations to explore potential upsides while mitigating the risk if they make a mistake.
Prevents unintended regressions that weren’t part of testing but exist in the product: Unintended side-effects can often be caught by using guardrail metrics and automatically detecting heterogeneous treatment effects.
Running a query-level experiment in practice
The hypothesis
Our current methodology used in MEx funnels of creating temp tables for CTEs that we reference several times in a query isn’t always helpful. Creating the temp table is only worth it if the dataset is sufficiently large.

To be a bit more formulaic…
IF we just use a CTE instead of a creating a temp table
THEN companies with smaller data sets will be more efficient
BECAUSE creating a temp table takes queueing time, compute and storage in Big Query that outweighs the helpfulness of referencing a temp table later on
RESULTING IN lower query latency and lower round trip times for those cases
The implementation
Setting up our first query-level experiment was quick and straightforward, and future iterations of query-level experiments will be even easier, since the existing ID type set up and additional metadata telemetry can be re-used.
Handling assignment
We start by generating an ID in every server request. That is, every time a user runs a Metrics Explorer Funnel query, a new ID is generated. We fetch our experiment with the experiment unit type set to that ID, and determine which test group (temp table or CTE) that query should be in.
Query event telemetry
A timer starts, the query is executed, and the timer is stopped. We log a Statsig Log Event with this ID, attaching the time along with other relevant metadata. In this case, we attached metadata that could impact how much data is read or how expensive the computations are, such as the number of steps in the funnel or whether the funnel joined data from multiple sources. We also used user-level information from the user object in this event (user_id, company_id) in our analysis as well.
The results:
As we had suspected, overall using a CTE instead of creating a temp table drove down user_mex_query_latency (the time it took the big query portion of a MEx response) and mex_funnel_trace (the roundtrip time for results to be displayed to a user).
However, for an outlier company with very large data volume, then creating temp tables was still worth it, as their bigquery portion of a MEx response, the metric user_mex_quer_latency_[company_name] increased when CTEs were used instead of temp tables.

There were other factors where we also wanted to understand if these factors impacted whether or not it was worth it to create a temp table:
Expensive joins: In some query types, this temp table would contain a relatively expensive join. This happens when we want to group by or filter by a property that’s not attached to the event, like experiment/gate group or cohort status.
More funnel steps: When there are more funnel steps, the size of the temp table or CTE in question is more likely to be larger.
Grouping by a field: This tends to make subsequent steps in the query more expensive, so having using a temp table may be more efficient when a group by is in place.
So we turned to the Explore tab to dig into some of these scenarios:

This process allowed us to map out our decision space for when to use a temp table vs. a CTE:
| Large Company | Other Companies | |
|---|---|---|
| Query joins in experiment/gate group assignment | Use a Temp Table | Use a Temp Table |
| Query joins in cohort participation status | Use a Temp Table | Use a CTE |
| Query has group by | Use a Temp Table | Use a CTE |
| Query has no join and no group by | Use a CTE | Use a CTE |
(Number of steps in the funnel doesn’t impact our decision on whether to use a temp table or a CTE)
This has allowed us to be data-driven when making a determination around whether a temp table should be created for MEx funnel queries, and quickly scale learnings about methodologies which sometimes help and sometimes hurt performance.
Request a demo
